Media Ingest
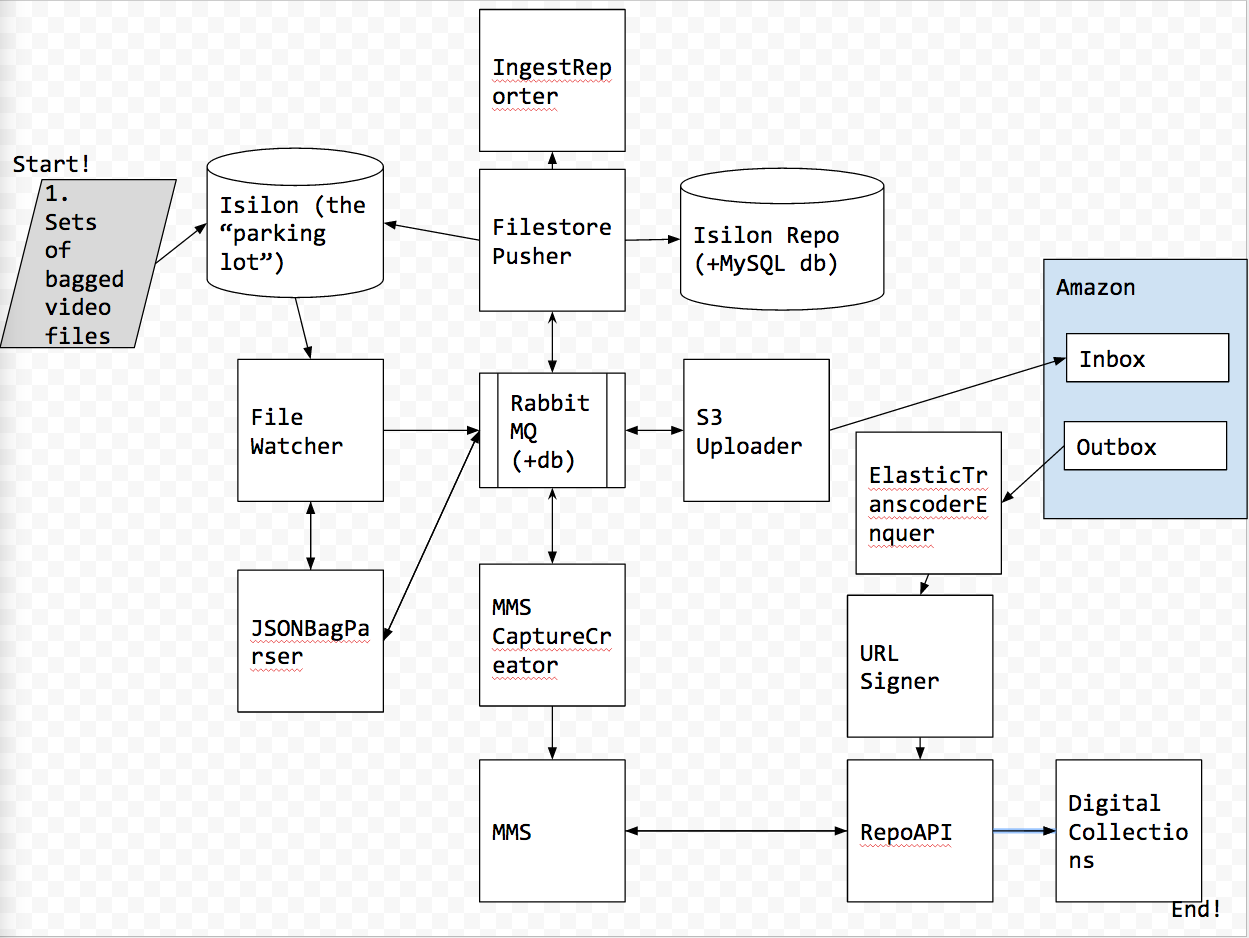
Cluster
Information about the QA and Production clusters to help people who want to access the machines.
QA/Development Tier
This tier is called both “QA” and “Development”. It’s the same tier. It’s our one-and-only pre-production tier.
| Apps | IPs |
|---|---|
| Filewatcher, FilePusher | 10.224.6.14 |
| Capture Creator, ET Enqueuer, S3Uploader | 10.224.6.15 |
| JSON Bag Validator | 10.224.6.16 |
Production
| Apps | IPs |
|---|---|
| Filewatcher (VideoProcessor) | 10.224.6.32 |
| FilePusher (FilestorePusher) | 10.224.6.31 |
| Capture Creator, ET Enqueuer, S3Uploader | 10.224.6.33, 10.224.6.34, 10.224.6.36 |
| JSON Bag Validator | 10.224.6.17, 10.224.6.19, 10.224.6.20 |
Access
All machines have a sudo-powered user named developer who can login with with nypl-digital-dev private key (in parameter store).
RabbitMQ
Many applications in media-ingest talk to each other via RabbitMQ queues.
Read more about our Rabbit setup here.
Special Directories
“hot folder” is where PAMI drops bags to be seen by FileWatcher. “upload purgatory” is where FileStorePusher drops files that will uploaded by S3Uploader.
QA
- hot folder:
/ifs/prod/video_ingest/qa_parking_lot - upload purgatory:
/ifs/prod/video_ingest/qa_media_ingest_pending_s3_upload
Production
- hot folder:
/ifs/prod/parking/lpa/Video - upload purgatory:
/ifs/prod/parking/media_ingest_pending_s3_upload
Deploying
We use NYPL’s Bamboo to build & deploy all of the applications.
Eccentricities
- Some (mostly QA/Development) tiers are deployed through a build, not deploy job. Other apps have distinct build, and deploy jobs.
- Some deployments work by bamboo calling Capistrano scripts contained in the app’s repo. Other deployments SSH into the machines directly
and do the work. (
git pull origin [BRANCH] && systemctl restart [SERVICE-NAME])
We should seek to unify how the apps are deployed.
In general, The QA/Development tier is deployed from the apps’ “qa” branch and the production tier is deployed from the “production” branch. We should seek to have each app’s README document its git/deploy workflow.
Re-deploying is a good way to restart services.
The Application Machines…
SSH Access
As of writing, we have user-specific linux users, tied to actual people’s SSH keys and/or passwords to get onto the machine. SEB-1580 is a ticket for getting a general developer user account for those machines.
Running Commands
systemd
All machines use systemd’s systemctl command to stop/start/restart processes. Each application’s Capistrano scripts end up calling systemctl commands, post deploy to restart the process. (example)
.
See each applications’s “Process Control” below for info about how to manually stop/start processes.
Finding WHERE Apps Are on a Machine
systemdhas a configuration.servicefile that has stop/start commands and rules.- If you
catthe.servicefile, the rules usually tell you where the app lives.
Example (JSON bag parser Rabbit Consumer):
$ systemctl status json_bag_parser_rabbit_consumer.service
● json_bag_parser_rabbit_consumer.service - JSON Bag Parser Rabbit Consumer
Loaded: loaded (/etc/systemd/system/json_bag_parser_rabbit_consumer.service; static; vendor preset: disabled)
Active: active (running) since Fri 2019-10-11 14:28:17 EDT; 6 days ago
Main PID: 26644 (ruby)
CGroup: /system.slice/json_bag_parser_rabbit_consumer.service
└─26644 ruby /opt/cap/json_bag_parser/current/consume_json_bags_from_rabbit.rb run
This tells you the config file lives in /etc/systemd/system/json_bag_parser_rabbit_consumer.service.
cat /etc/systemd/system/json_bag_parser_rabbit_consumer.service
[Unit]
Description=JSON Bag Parser Rabbit Consumer
[Service]
Type=simple
User=git
Group=git
WorkingDirectory=/opt/cap/json_bag_parser/current/
ExecStart=/usr/bin/bash -lc 'bundle exec ruby /opt/cap/json_bag_parser/current/consume_json_bags_from_rabbit.rb run'
TimeoutSec=30
RestartSec=15s
Restart=always
This tells you the app lives in /opt/cap/json_bag_parser/current.
To list all processes under systemd’s control.
$ systemctl list-units
UNIT LOAD ACTIVE SUB DESCRIPTION
proc-sys-fs-binfmt_misc.automount loaded active waiting Arbitrary Executable File Formats File System Automount Point
sys-devices-pci0000:00-0000:00:11.0-0000:02:01.0-ata1-host2-target2:0:0-2:0:0:0-block-sr0.device loaded active plugged VMware_Virtual_SATA_CDRW_Drive RHEL-7.2_Server.x86_64
sys-devices-pci0000:00-0000:00:15.0-0000:03:00.0-host0-target0:0:0-0:0:0:0-block-sda-sda1.device loaded active plugged Virtual_disk 1
sys-devices-pci0000:00-0000:00:15.0-0000:03:00.0-host0-target0:0:0-0:0:0:0-block-sda-sda2.device loaded active plugged LVM PV QkZtEs-qOli-IwqV-wtHW-mWvo-Et6A-F4ltKI on /dev/sda2 2
...snip
json_bag_parser.service loaded active running JSON Bag Parser Resque Worker
json_bag_parser_rabbit_consumer.service loaded active running JSON Bag Parser Rabbit Consumer
kdump.service loaded active exited Crash recovery kernel arming
kmod-static-nodes.service loaded active exited Create list of required static device nodes for the current kernel
lvm2-lvmetad.service loaded active running LVM2 metadata daemon
systemctl list-units is verbboooossseee so maybe pipe it to grep with a likelike search term like:
$ systemctl list-units | grep -i json
json_bag_parser.service loaded active running JSON Bag Parser Resque Worker
json_bag_parser_rabbit_consumer.service loaded active running JSON Bag Parser Rabbit Consumer
Applications
FileWatcher (Processor)
Watches for bags, validates them, and sends them to be processed.
Listens to:
PAMI putting a bag into the hot folder
Talks to:
CaptureCreator, FileStorePusher, JSONBagParser (via Rabbit)
Process Control:
sudo systemctl [status|start|stop|restart] VideoProcessor.service
Source:
https://github.com/NYPL/Processor
JSONBagParser
The executable that reads from Rabbit and adds to redis queue:
sudo systemctl [status|start|stop|restart] json_bag_parser_rabbit_consumer.service
The harder working Resque worker:
sudo systemctl [status|start|stop|restart] json_bag_parser.service
Listens to:
Manual command OR FileWatcher
Talks to:
FileStorePusher (via Rabbit)
Source control:
https://github.com/NYPL/media-ingest-json-bag-parser
CaptureCreator
Listens to:
FileWatcher (via Rabbit)
Talks to:
MMS
Process Control:
sudo systemctl [status|start|stop|restart] capture-creator.service
Source control:
https://bitbucket.org/NYPL/media-ingest-capture-creator
FileStorePusher
Listens to:
FileWatcher (via Rabbit)
Talks to:
Isilon
Process Control:
sudo systemctl [status|start|stop|restart] FilestorePusher.service
Source control:
https://bitbucket.org/NYPL/filestorepusher
S3Uploader
Listens to:
FileStorePusher (via Rabbit)
Talks to:
Uploads files to S3.
Process Control:
sudo systemctl [status|start|stop|restart] s3-uploader.service
Source control:
https://bitbucket.org/NYPL/media-ingest-s3-uploader
ElasticTranscoderEnqueuer
Listens to:
SQS Queue that gets pushed to via S3 Events when S3Uploader uploads a file.
Process Control:
sudo systemctl [status|start|stop|restart] elastic-transcoder-enqueuer.service
Source control:
https://bitbucket.org/NYPL/media-ingest-elastic-transcoder-enqueuer
URLSigner
Source control:
https://github.com/NYPL/rights-aware-cloudfront-url-signer
IngestReporter
Lives at: http://ingest-reporter.nypl.org/ It’s hosted on Elastic Beanstalk. It’s a rails app with a Rabbit consumer that runs alongside it to insert records in its database once a file is done being ingested.
Listens to:
FileStorePusher (via Rabbit)
Source control:
https://bitbucket.org/NYPL/ingest_reporter
mock_filewatcher
MockFilewatcher is a Ruby gem for testing media-ingest.
Source control: https://github.com/NYPL/mock_filewatcher
Log Aggregation & Failure Notification
Logs
All services have their logs aggregated and set to our loggly account. OPS (Ho-Ling/Brett) are admins and can give you an account.
Failure Notifications
We use loggly alerts to get notified about exceptions. Like CloudWatch alerts, they are filters/metrics that send an email once they reach a certain threshold.
The alerts are configured to send an email to media.ingest.failures@nypl.org. We’ve configured Jira to poll that inbox and automatically create tickets in a project named MIF for each exception.
Metadata Tools
ami-tools
ami-data
MediaIngest JSON schema repository
Mapping of metadata-JSON to MODS